TOFU
Toward Obfuscated Federated Udates - Encoding Weight Updates Into Gradients From Proxy Data for Communication-Efficient and Privacy-Enhanced Federated Learning.
Motivation
Federated Learning (FL) allows multiple clients to collaboratively train models without directly sharing their private user data. This is typically managed by a central server that aggregates weight updates from clients. While promising, this approach faces significant challenges:
- Communication Cost: Repeatedly sending large weight updates between clients and the server is expensive, especially as models grow in complexity (e.g., a VGG13 model has 9.4 million parameters, resulting in 36 MB of data per round per device).
- Privacy Concerns: Standard federated averaging techniques are vulnerable to data leakage, where gradients can be inverted to reconstruct the original training data. While encryption can mitigate this, it adds further overhead.


TOFU was developed to address these critical issues of communication efficiency and data privacy in federated learning.
Overview of TOFU Methodology
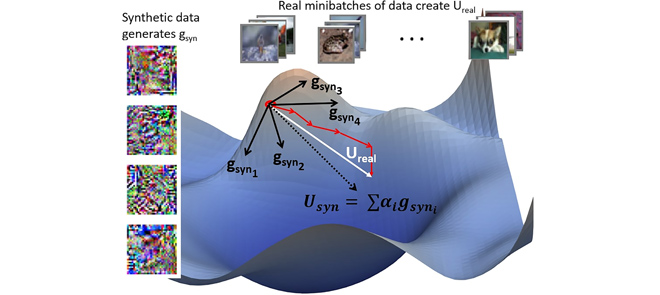
TOFU (Toward Obfuscated Federated Updates) introduces a novel algorithm where clients generate and share proxy data instead of their direct weight updates. The core idea is to encode the client’s actual weight update (obtained from learning on its local data) into the gradients of this small set of synthetic proxy data.
Key aspects of the TOFU methodology:
- Encoding Weight Updates:
- Each client first computes its local weight update ($U_{real}$) after training on its private data.
- TOFU then generates a small synthetic dataset ($D_{syn}$) comprising images and soft labels by optimizing it such that the gradients derived from this $D_{syn}$ (termed $U_{syn}$) closely match the direction of $U_{real}$. This is achieved by minimizing the cosine similarity between $U_{real}$ and $U_{syn}$.
- The synthetic images often resemble noise, obfuscating the true underlying user data.
- Communication:
- Clients send this low-dimensional proxy data (images, soft labels, and scaling/weighting factors) to the server instead of the high-dimensional weight updates. For instance, CIFAR-10 images have only 3072 pixels, and TOFU might use under 100 such images, leading to significant data reduction compared to sending millions of weight parameters.
- The server decodes the proxy data to get the encoded weight update for each client, aggregates them, and can similarly encode the aggregated update into new proxy data for down-communication to clients.
- Enhanced Privacy:
- Since the proxy data resembles noise, even if data leakage attacks perfectly reconstruct inputs from the shared gradients, they would invert into this unrecognizable noise, not the original sensitive user data.
- The use of soft labels and weighted averaging of gradients from synthetic data further discourages attacks that rely on one-hot labels or specific gradient structures.
- Hybrid Approach for Accuracy:
- While encoding approximates gradients and can lead to a slight accuracy drop, TOFU proposes a hybrid approach.
- For most of the training, the communication-efficient and privacy-enhancing proxy data exchange is used.
- Towards the end of training, a few rounds of sharing true, full weight updates (which should be encrypted) can be performed to recover any accuracy loss. This phase is short, minimizing the overhead of expensive encryption.


Results and Performance
TOFU’s effectiveness was demonstrated on MNIST and CIFAR-10 datasets, showing significant improvements in communication efficiency while maintaining high accuracy and enhancing privacy.
Key Results:
- Accuracy and Efficiency:
- On MNIST and CIFAR-10, TOFU enabled learning with less than 1% and 7% accuracy drops, respectively, when primarily using proxy data.
- These drops can be recovered by a few rounds of full (encrypted) gradient exchange. For example, only 3 and 15 full weight update rounds were needed for MNIST and CIFAR-10, respectively, to regain accuracy.
- This hybrid approach achieved near-full accuracy while being 4x more communication efficient on MNIST and 6.6x on CIFAR-10 compared to standard Federated Averaging (FedAvg).
- In single-device setups on CIFAR-10 (VGG13 model), TOFU achieved an average accuracy drop of only 3% with 17x communication efficiency using full-sized synthetic images.
- Downsampling synthetic images (e.g., reducing to a single channel or smaller dimensions) provided further communication gains (e.g., grayscale images led to 49x efficiency with a 5% accuracy drop).
- Privacy Enhancement:
- Empirical tests showed that while full gradient exchanges are vulnerable to various data leakage attacks (like IG, DLG, GradInversion, GIAS), the synthetic gradients decoded from TOFU’s proxy data maintained privacy, with reconstructed images resembling noise. This holds even when attacks are modified for different label reconstruction strategies.
- Data obfuscation generally increases with a larger synthesis frequency (Synfreq), although privacy is maintained at various settings. TOFU can fail to maintain privacy if the batch size for synthetic data generation is 1, but succeeds for batch sizes greater than 1.

- Computational Overhead:
- TOFU introduces additional computational costs on the client-side for creating the synthetic data.
- The overhead is primarily affected by the number of synthetic images (Nimgs) and the number of optimization iterations for encoding, not by the synthesis frequency or batch size of the true data.
- Decoding the synthetic data is very fast (lesser than 10 milliseconds in experiments), with the majority of the compute time attributed to the encoding algorithm.
TOFU offers a promising direction for building more practical and secure federated learning systems, especially where communication bandwidth is a bottleneck or privacy is paramount. The benefits of TOFU in terms of communication efficiency are expected to grow with increasing model sizes, as input data dimensions typically remain fixed.
You can find more details in the full paper: (Nagaraj et al., 2024)